
“There are only two hard things in computer science – naming things and cache invalidation” – Phil Karlton
Introduction
Caching is often associated with fast, performant applications. When done correctly, it gives you amazing performance results. However, there are several traps that can break your app in subtle ways. I’ll explain them in this post.
Caching
Caching is the process of storing pre-computed or pre-fetched data in a fast-to-access temporary store (named cache) for faster retrieval later on.
The main objective here is to save computational resources (calculating something) or database load (fetching from database) and time.
Thanks to caching, requests that normally take seconds, can be reduced to milliseconds.
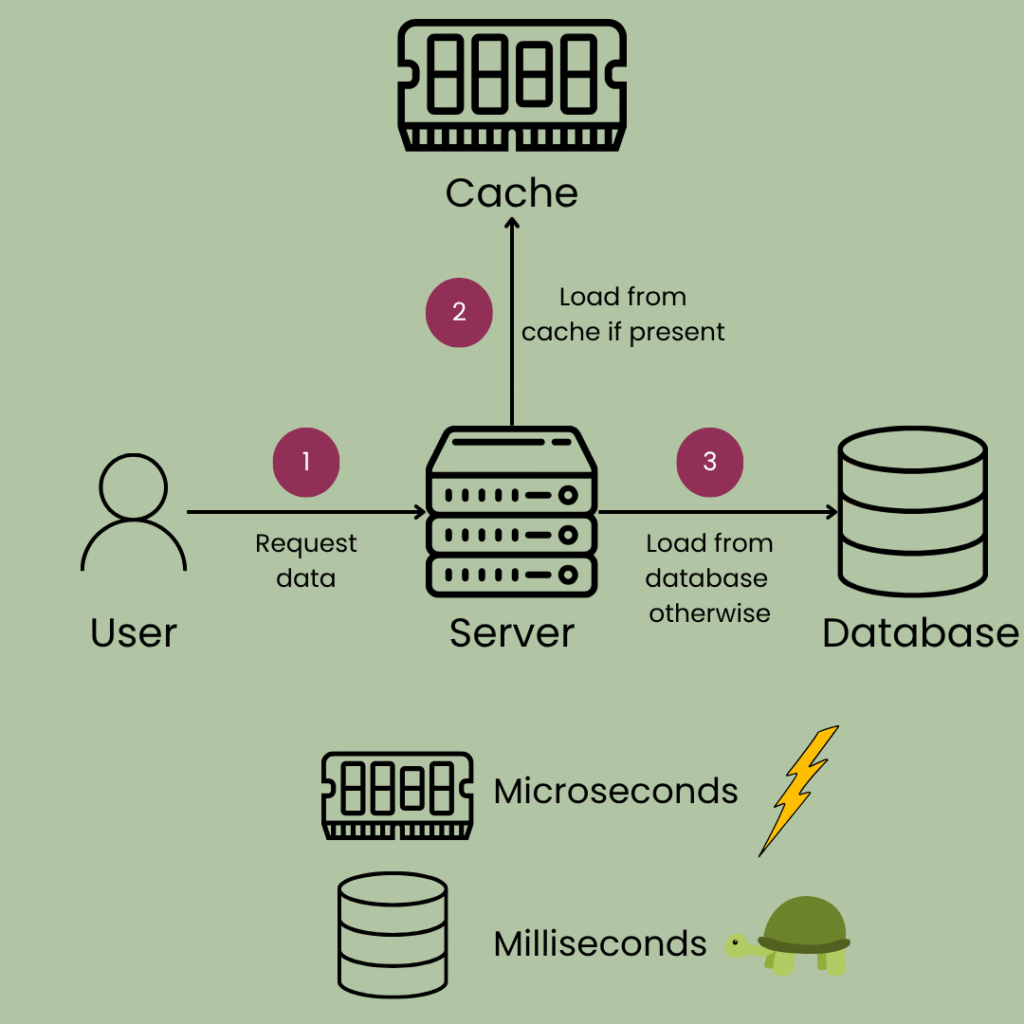
Alas, caching is not a silver bullet. Let’s explore the traps.
Cache Invalidation
Case study
Let’s imagine you visit the website of your favorite movie theater to buy tickets for the new thriller premiering Friday night. The website claims the ticket costs $10. Happy with that, you add the ticket to your cart and proceed to checkout. However, on the checkout page it clearly states that the amount due is $20, even though you only bought one ticket. What happened here?
This is a classic example of cache invalidation gone wrong.
At some point, the theater updated the price but the cache invalidation request failed (e.g. due to temporary network failure). That’s why different parts of the system were serving different data.

Ensuring that caches are properly invalidated is notoriously hard. If you overdo it, you lose the invaluable performance benefit. If you neglect it, you end up serving incorrect data.
Cache Consistency
The consistency challenge is partly related to the previous one. Let’s imagine that the ticket price invalidation request did not fail and it went through. There would still be a period of time when the ticket price in the database ($20) would be different than the one in the cache ($10). This happens because the propagation of change takes time – from sub-second intervals, up to several seconds. When you checked the ticket price at exactly this window, you would be getting incorrect data, even though invalidation was successfully executed. This is called inconsistency period.
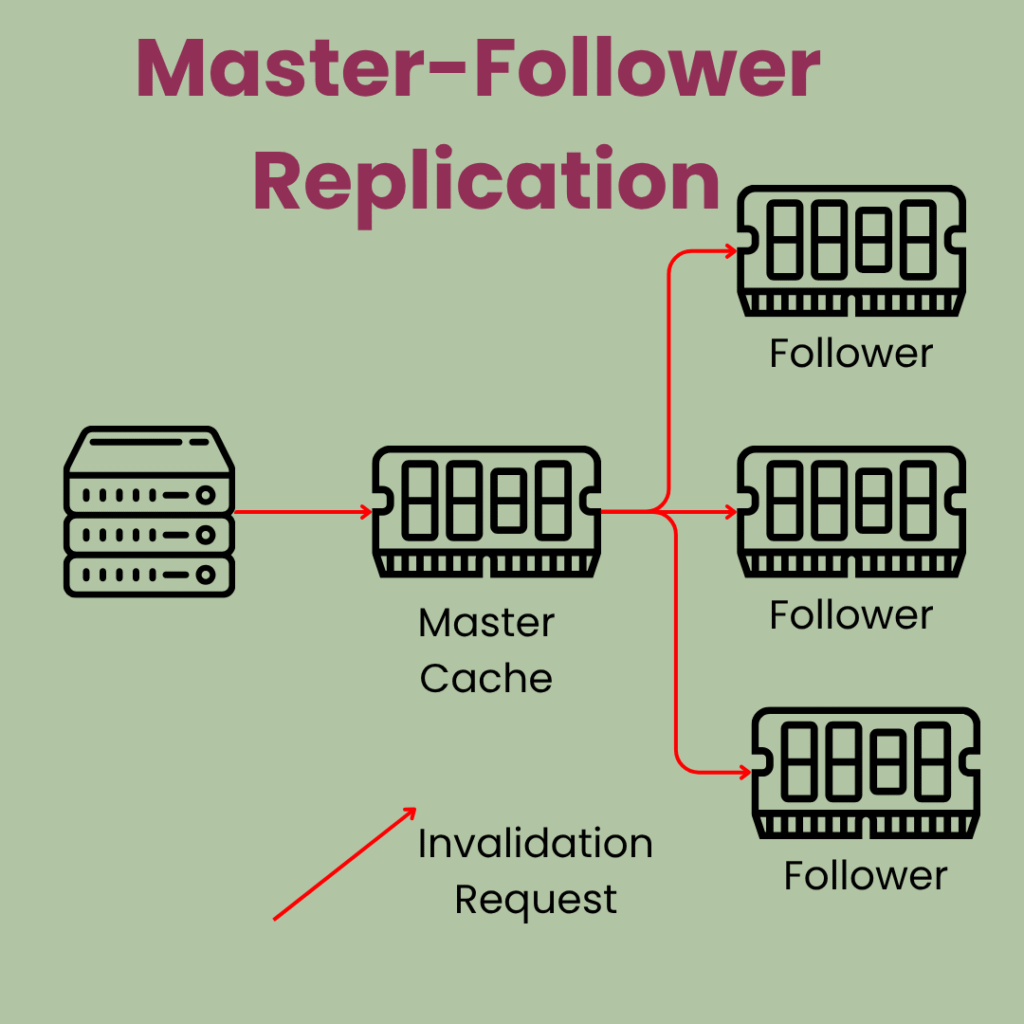
Situation gets even more complicated when we have multiple caches (for horizontal scalability) where one cache (master) replicates data to other caches (followers), which makes the inconsistency period possibly longer.
Cache Stampede
Case Study
Imagine your website is selling concert tickets. The number of available tickets is loaded from the database every five minutes and put in cache. This means that each cache key expires every 5 minutes.
Now, you are planning to start selling tickets to the concert of a very famous band. There are hundreds of thousands of interested people.
It’s 9 am and the cache key for the concert expired. At the same time, hundreds of thousands of users are refreshing the webpage. Each of those requests hit the database. What’s more, on each successful purchase, the cache has to be invalidated, resulting in even more DB calls for the updated count!
- Response times skyrocket
- Some users get errors
- Others proceed to checkout with stale data (cache inconsistency!)
- Cache gets overwhelmed due to a huge number of writes
What just happened is called a cache stampede. When a popular cache key expires, multiple clients try to update it, resulting in bombarding the underlying data source and the cache itself.
Potential solutions to the problem might include
Locking
Only let one request through – this request will fetch the latest data and update the cache. Once this request has succeeded, let the others through.
Preemptive refresh
Update the value of the key before it expires.
Jitter
To prevent many popular keys from expiring at the same time, add random jitter to TTL (time to live) for each cache key
Cache eviction
Each cache has a limited size . We can only put a finite number of keys there. When your system grows, you need to decide how to delete data from cache. A few common approaches include
LRU (Least-Recently Used)
Remove the item that hasn’t been used for the longest time
LFU (Least-Frequently Used)
Remove the item which was read the lowest number of times
FIFO (First-In, First-Out)
Remove the oldest item in the cache
Random
Remove a random item from the cache
Each of these algorithms has its pros and cons. For example, the FIFO approach is extremely simple but can remove a popular key because it was added a long time ago.
The LRU, on the other hand, doesn’t consider how often an item was accessed, just how long time ago.
In practice, we often need a custom eviction algorithm, which can be a hybrid of the existing ones.
For example, you can use another metric, such as ‘weight’ (corresponding to the time needed to compute the value) and decide on eviction based on both frequency of use and weight.
Conclusion
Junior developers and architects consider cache as a simple way to boost an application’s performance. However, caching also yields tricky challenges that can break your app. Caching is non-trivial and mastering it can make the difference between a fast app and a flaky one.
Leave a Reply