
Recap: What is caching?
Caching is the process of saving a once-computed value with a view to retrieving it again later on, to avoid re-computations. This is a very complex subject with many pitfalls, you can read about them in my different article – here
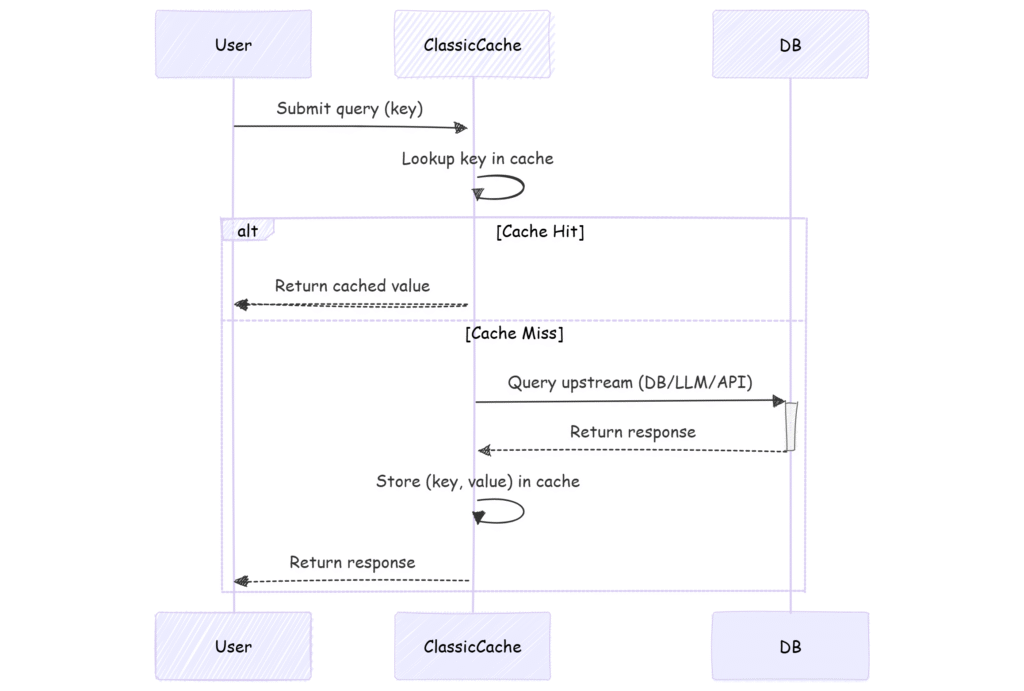
When we need to get the value, we first check if that’s already stored in the cache. If that is the case, we just return it. Otherwise, we hit the database (or API, or LLM) with out heavy query, get the response and update the cache. It will be available the next time we need it (unless the key is invalidated or expires…)
Challenges in GenAI systems
Let’s imagine you have implemented a sales support chatbot for a car dealership. User is able to ask questions and the system uses a RAG-based architecture to answer it. Now, let’s imagine the user asekd the following question
What financing services do you offer?
The system accepted the question and generated a response. The generation took 5 seconds and burned a few thousand tokens. The response was saved in cache.
Now, another user asks a different question
Tell me about the ways in which I can finance my new car
Which is basically the same question but saved differently. With a classical caching approach, this would result in a cache miss – there’s no way to know that these two questions are in fact the same. We would need to regenerate the response (latency) and pay for extra tokens.
Introduction to Semantic Caching
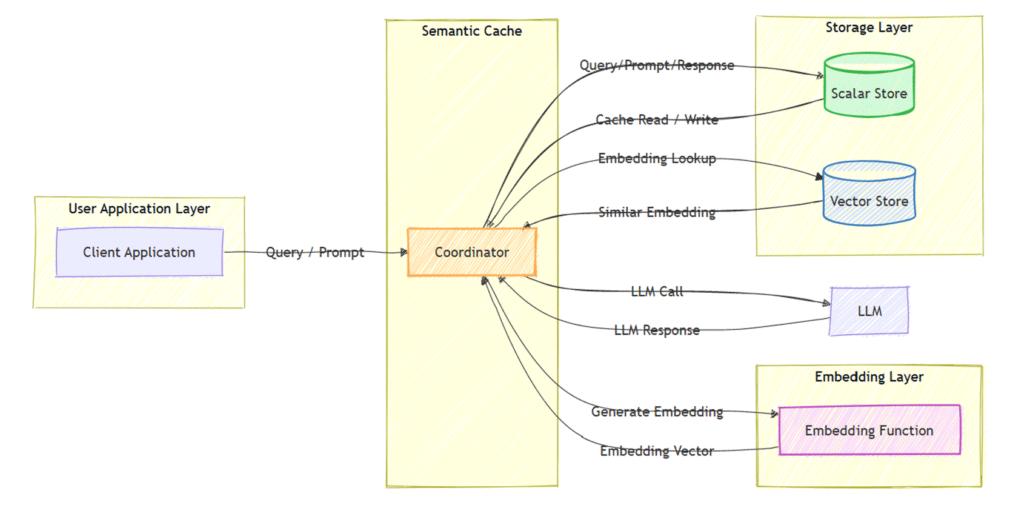
Architecture
Semantic Cache is built on top of classical caching. It consists of the following components
- Semantic Cache Coordinator
- Scalar Store (classical caching engine, for example Redis)
- Vector store
- Embedding Function (used to generate vector embeddings for the vector store)
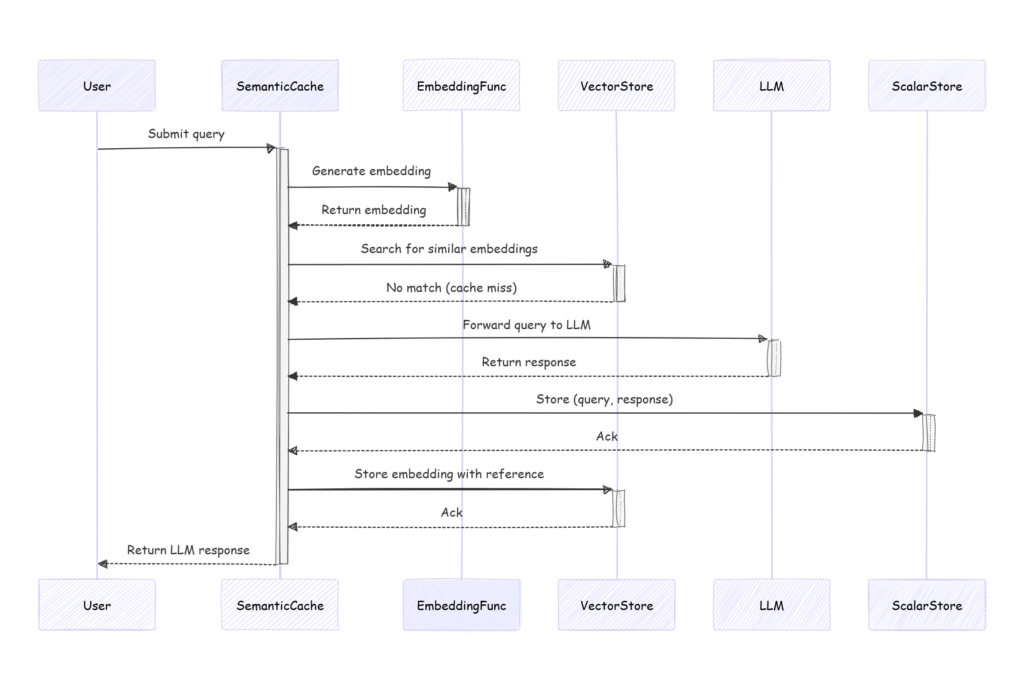
Cache insertion flow (Cache miss flow)
Let’s walk through the lifecycle of a user request and see how it works step by step.
- The user asks the question: “How can I finance my new car?”
- The query gets converted into a vector using the Embedding Function
- A similarity search is done on the Vector Store. We find all vectors in the vector store that are close to the vector representation of the user’s query.
- We haven’t found anything close enough (say – within the distance of 0.1)
- Typical RAG flow is performed and a response is generated.
- The Coordinator stores the response in the Scalar Store. The ID of the newly added item is returned to the Coordinator.
- The Coordinator stores the user’s query vector in the vector store. It attaches metadata pointing to the response’s ID in the Scalar Store
- Response is returned to the user
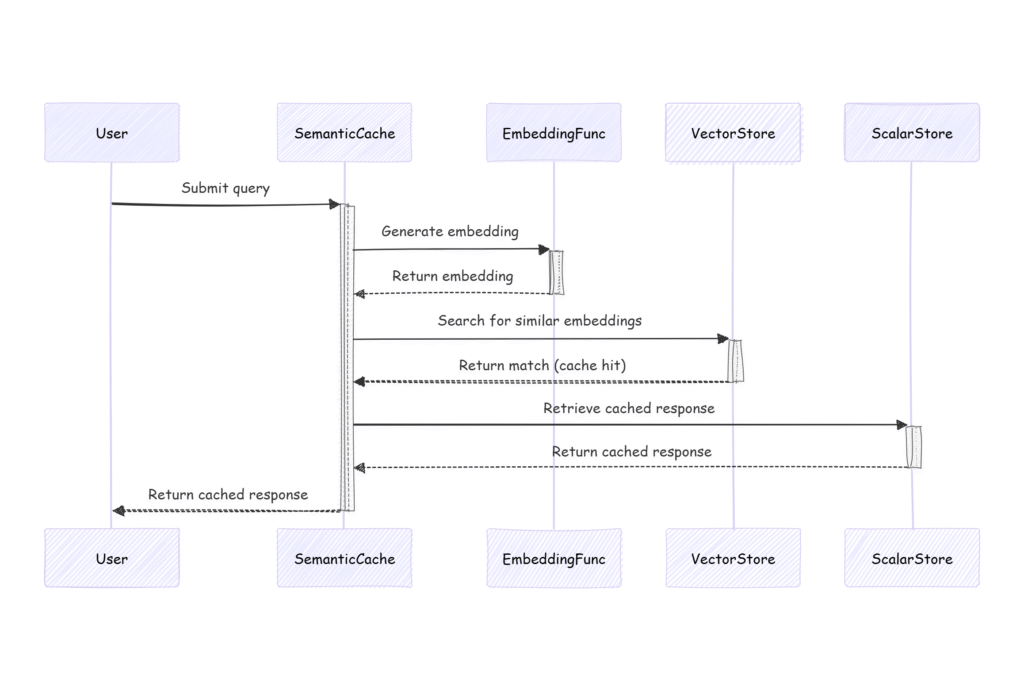
Cache retrieval flow (Cache hit flow)
Now, let’s imagine a different user uses the system.
- The user asks the question: “Which car financing options do you offer?”
- The SemanticCache uses Embedding Function to generate embeddings for the query
- The SemanticCache checks in the VectorStore for any very similar vectors (distance <0.1)
- VectorStore returns a very close vector (the one from the previous question)
- The SemanticCache gets the scalarStoreId from the vector’s metadata
- The SemanticCache retrieves the cached response from the ScalarStore
- The response is returned to the user
Cache Eviction
Cache Eviction is another challenging topic. Let’s imagine that the scalar store is already full and we need to evict an element from it to make room for a new key. This is the flow:
- Identify the evicted element from the ScalarStore
- Find the vector associated with the evicted element in the VectorStore (by the ID of the removed scalar element)
- Remove the vector from vector store
Semantic Cache trade-offs
Benefits
Decreased latency
SemanticCache lookup is way faster than a full RAG flow
Decreased generation costs
We will use fewer completion tokens, resulting in decreased LLM expenses.
Scales with repetition
In certain systems (e.g. support chatbot), users are bound to ask very similar questions. Such systems greately benefit from this approach.
Drawbacks
Storage overhead
You have to maintain two stores – a scalar one and a vector one, which adds extra complexity as well.
Approximation risk
Two similar questions might in fact expect different answers. We can tweak it by changing the proximity threshold. Setting the threshold too high (we accept only a very small distance) will significantly increase the number of cache misses, adding extra latency to the system.
However, setting the threshold too low will result in multiple cache-hits even though the response does not answer the query the way it should.
Bias towards “hot” content
Frequently asked questions (in different wording) will generate a lot of vectors which will populate the vector store. We need a “merging” strategy, otherwise the cache will be overpopulated by such content.
Summary
Semantic caching extends classical caching by enabling reuse of responses for semantically similar queries — not just exact matches. In GenAI systems, this can lead to significant reductions in both response latency and LLM usage costs.
However, this approach comes with trade-offs. Maintaining both a vector and scalar store introduces complexity, and tuning similarity thresholds requires careful balance to avoid mismatches or cache misses. Additionally, eviction and vector deduplication strategies are critical to ensuring long-term performance and scalability.
When designed thoughtfully, semantic caching can be a powerful optimization layer in modern AI-driven applications — especially those handling large volumes of repetitive user input.
Leave a Reply