Introduction
Most of modern GenAI based systems are powered by a Large Language Model (LLM) under the hood. If you are a tech startup, working on your pet project or even operate in a consulting commpany, chances are you are not using a self hosted model (they have great use cases but the maintenance overhead and tricky scalability are often repellents). In this case, the operational cost of the system is directly proportional to the number of LLM tokens used.
Introduction to Tokens
The full text that you are sending to the chat completion model (system prompt, previous messages, current message) are tokenized by a dedicated model (called tokenizer) in order to simplify further processing.
There are two types of tokens
- Input tokens — Tokens in our request
- Output tokens — Tokens in model output
Usually, the output tokens are way more costly.


You can use a tool like token-counter.app to determine the number of tokens in your prompt.
Now, let’s discuss different ways to cost-optimize your solution
Method One: Request concise style and limit output tokens (Prompt Engineering)
The first thing we can do is to influence the style in which the response is generated. By adding certain phrases to the initial prompt, such as
- Answer as concisely as possible
- Limit your response to X sentences
- Be brief
we can significantly limit the length of the response.
For example, consider the following prompt
Based on the context, answer the question
Context: PhantomDrill is a company that manufactures innovative drills, allowing one to mount objects to the wall without making physical holes, by interfering with molecular structures.
Question: What is unique about PhantomDrill products?
This is the response that was generated
Based on the given context, the unique feature of PhantomDrill products is their ability to mount objects to walls without making physical holes. Instead of traditional drilling methods, PhantomDrill’s innovative drills work by interfering with molecular structures. This technology allows users to securely attach items to walls without causing visible damage or leaving holes behind.
Now, let’s add simple “answer concisely” to the end of the prompt. We have obtained the following result
PhantomDrill products uniquely mount objects to walls without making physical holes by interfering with molecular structures.
Apart from style request, we can also physically limit the number of output tokens that will be generated by the model. For example, this is what the parameter looks like in the Claude API.

This setting guarantees that we will not exceed the threshold, however, occasionally we might need to handle the problem of incomplete responses, by analyzing the stop_reason.
Method Two: Use Prompt Caching
In December 2024, the new caching feature was introduced to Antrophic. It is also present in OpenAI, although it works a bit differently.
Proper caching allows us to optimize cost of certain, repetitive prompts by up to 90% (refer to the table)

How does it work?
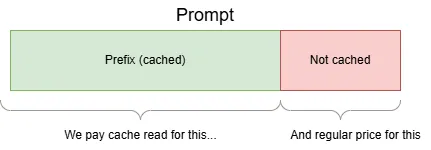
- We request that certain prompt of length 2024 tokens be cached (by setting the cache_control field)
- The completion is executed for the first time. At this stage, we have to pay extra for the prompt caching.
- Now we execute a new prompt, similar to the previous one. The first 1408 tokens (prefix) are identical and there are 600 tokens outside the prefix.
- We pay the reduced cache hit price for 1408 tokens and the regular input token price for the remaining 600 tokens.
As a side effect, prompt caching also improves performance by reducing completion time.
These are great use cases for prompt caching:
- Document context — the content of the document can be cached and subsequent prompts read its entire content from cache
- Many-shot prompting — all the examples can be cached
- Conversational chatbot — previous messages are read from cache
Method Three: Use a combination of models
Most LLM providers have serval models available in their offer. The models differ by their respective capabilties. For example:
Antrophic
- Claude 3.5 Haiku — cheap and performant model with lower capabilities
- Claude 3.5 Sonnet —the most powerful (and expensive) model for advanced use cases
Amazon
- Nova Micro
- Nova Lite
- Nova Pro
OpenAI
- gpt-35 turbo
- gpt-4o-mini
- gpt-4o
The key is to understand that you might not need the most capable model for all use cases.
For example — let’s imagine you are working on a RAG Chatbot for your company. There are three main branches — Finance, Support and Marketing
We have different agents for all branches.
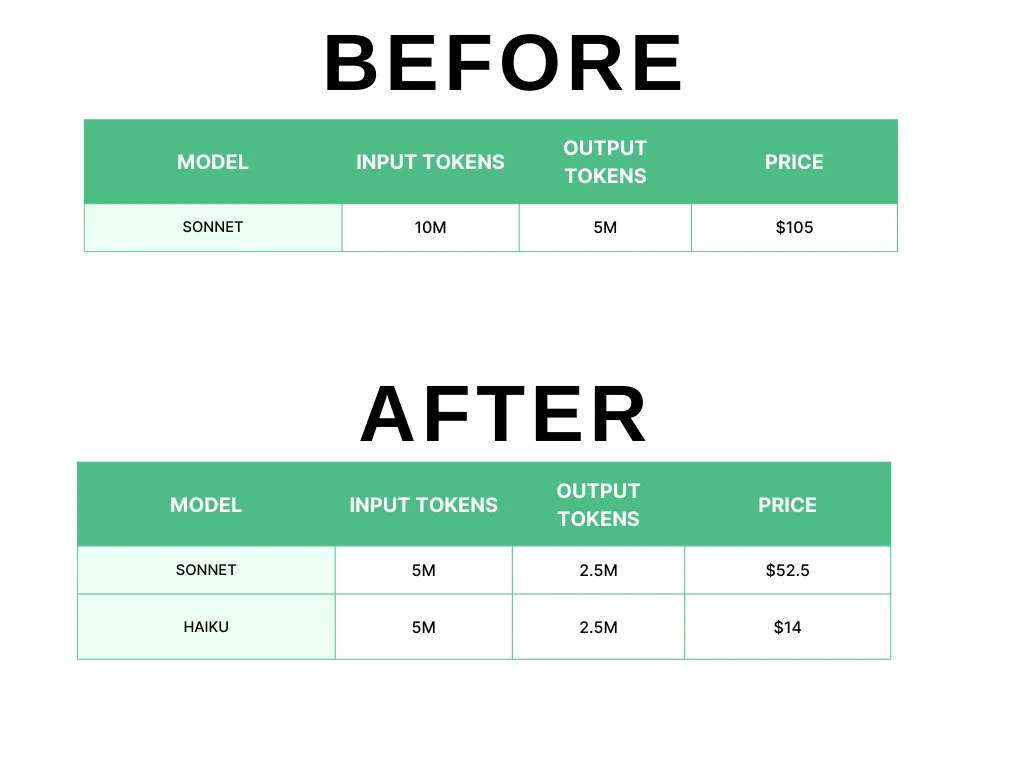
Let’s assume that the original implementation uses Sonnet 3.5 everywhere.
Every month, your system ingests 10M tokens and generates 5M output tokens.
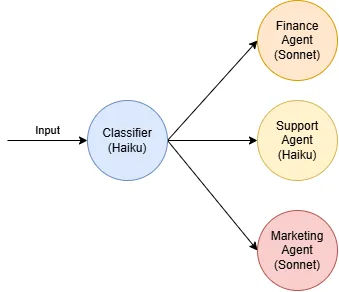
After some research you have realized that you do not need the most powerful model to do all the work.
- Haiku is good enough for classification
- Haiku is also good enough for answering basic support enquiries
You have re-architected the system to utilize Haiku for less demanding activities.
The results are represented in the table
Method Four: Use Message Batching
Message batching is a feature that was released in late 2024.
It allows you to execute multiple LLM requests for a significantly reduced token rate, given that you are willing to wait for the response.Your application is then responsible for verifying whether the request has already been processed.
Both Antrophic and OpenAI provide a 50% discount for batched requests and promise to deliver the response within 24 hours.
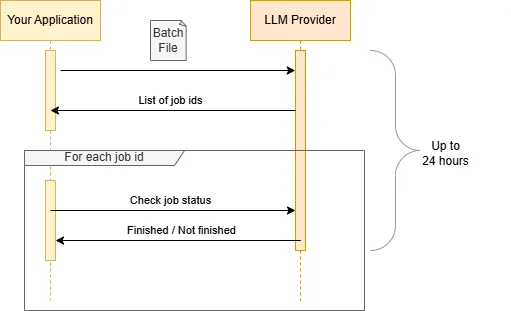
Not all use cases are applicable for the use of the Batching API. However, many projects could benefit from it.
- Document analysis — Analysis of multiple documents, such as summary and categorization, that does not need to be completed in a timely manner.
- Translations — LLM-powered translation of artifacts, such as blog posts, product descriptions or customer reviews that must later be analyzed by a human — it does not need to be completed on the spot, we can wait for the result for reduced price.
- Research — Drawing conclusions from a large number of surveys can be performed in the background and the results can be pushed to interested parties on completion.
Summary
The cost of large-scale LLM-based solution can quickly get out of hand. Good understanding of your non-functional and quality-attribute requirements, good prompt library and awareness of LLM-provider APIs (such as batching and caching) are key to keeping your expenses at a reasonable level.
Leave a Reply